 >
>
Concept Graph & Resume using Claude 3 Opus | Chat GPT4o | Llama 3:
Resume:
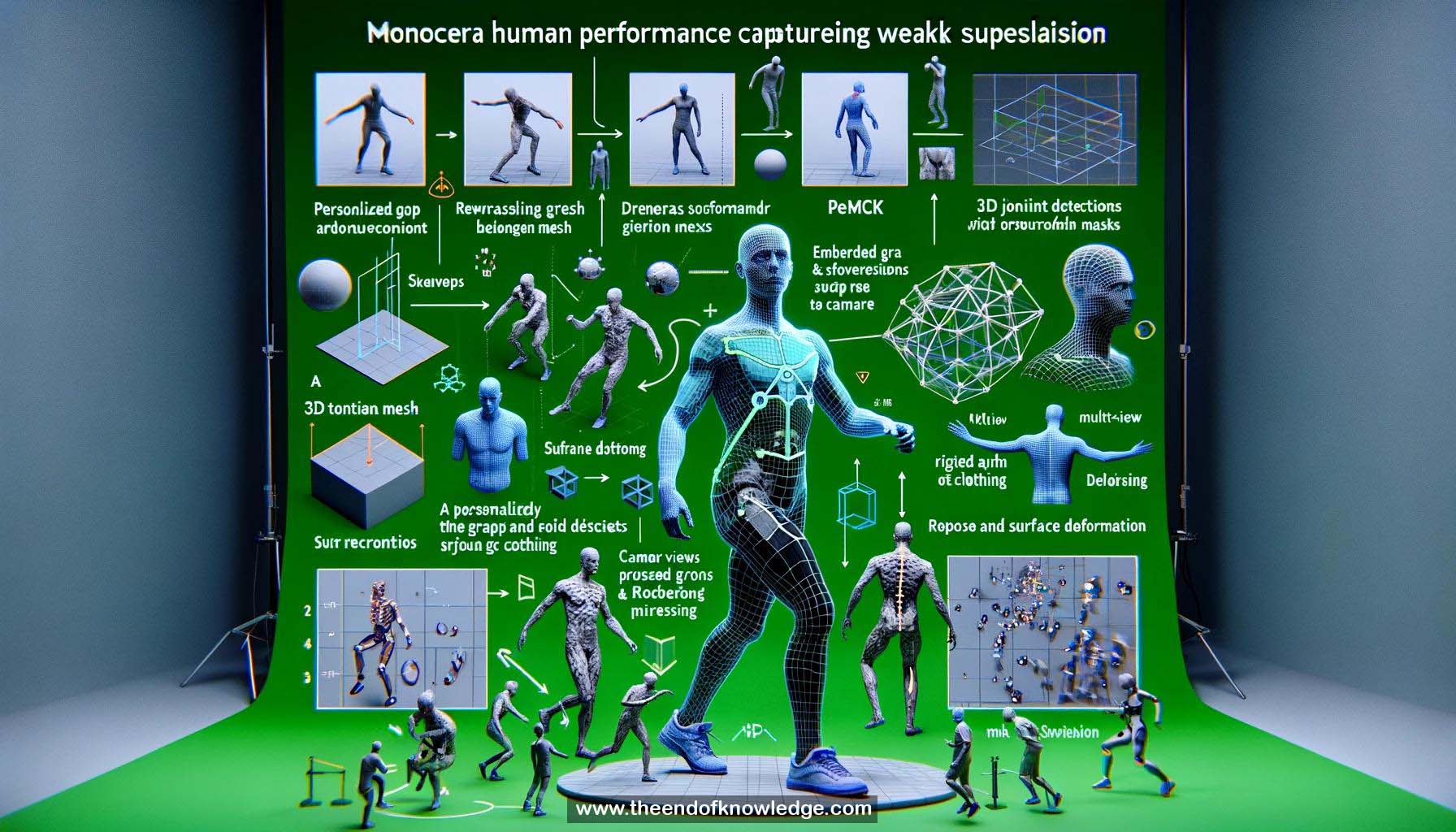
1.- DeepCAP: monocular human performance capture approach using a single RGB camera.
2.- Captures pose and clothing deformation for realistic virtual characters.
3.- Weakly supervised training prevents complicated data processing.
4.- Monocular setting is challenging due to depth ambiguities and high-dimensional problem.
5.- Previous work: template-free, parametric body models, and template-based methods.
6.- DeepCAP uses a personalized 3D template mesh with an embedded graph and skeleton.
7.- PoseNet regresses the skeleton pose, and DepthNet regresses surface deformation in canonical pose.
8.- Networks are weakly supervised with multi-view 2D joint detections and foreground masks.
9.- Differentiable 3D to 2D modules are required for loss evaluation.
10.- Capture setup: multi-camera green screen studio for training.
11.- PoseNet outputs 3D landmark positions in camera and root-relative space.
12.- Global alignment layer computes and applies rotation and translation for global 3D landmark positions.
13.- Multi-view sparse keypoint loss ensures 3D landmarks project onto 2D joint detections.
14.- DepNet regresses per-node rotation angles and translations of the embedded graph.
15.- Deformation layer combines regressed pose and deformation using embedded deformation and dual quaternion skinning.
16.- Global alignment layer is applied to obtain global vertices and landmarks.
17.- Multi-view sparse keypoint loss is applied for posed and deformed markers.
18.- Silhouette loss enforces model silhouette to match image silhouette for dense vertex supervision.
19.- Comparison to LifeCap shows improved 3D pose and plausible deformation of invisible surfaces.
20.- Comparison to implicit surface methods demonstrates consistent geometry over time and avoids missing limbs.
21.- Multi-view intersection over union measures surface reconstruction accuracy.
22.- DeepCAP outperforms previous work by accounting for clothing deformations and consistent 3D cloth deformation prediction.
23.- Weakly supervised training using multi-view 2D joint detections and foreground masks.
24.- Differentiable 3D to 2D modules enable loss evaluation during training.
25.- Personalized 3D template mesh with embedded graph and skeleton is used for pose and deformation regression.
26.- PoseNet and DepthNet are the two main networks in the DeepCAP approach.
27.- Global alignment layer ensures global 3D landmark positions for loss computation.
28.- Deformation layer combines regressed pose and deformation using embedded deformation and dual quaternion skinning.
29.- Silhouette loss and multi-view sparse keypoint loss provide dense and sparse supervision, respectively.
30.- DeepCAP achieves realistic human performance capture with consistent geometry and clothing deformation from a single RGB camera.
Knowledge Vault built byDavid Vivancos 2024