 >
>
Concept Graph & Resume using Claude 3 Opus | Chat GPT4o | Llama 3:
Resume:
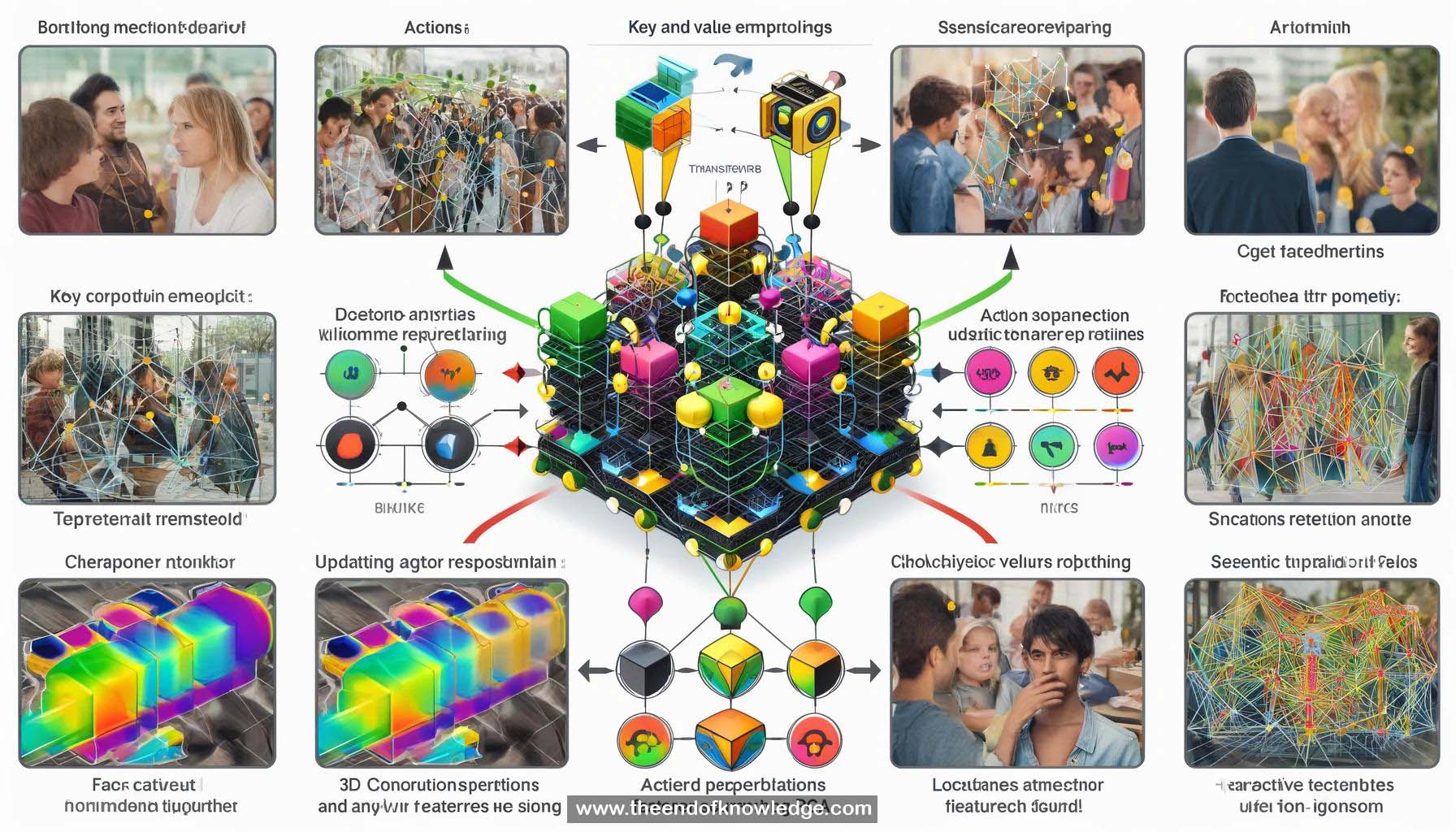
1.- Video Action Transformer Network aims to localize actors and recognize their actions in video clips.
2.- Spatio-temporal action detection is the technical term for this task, experimented on the AY dataset.
3.- Standard solution involves extracting 3D convolution features, center frame features, and using region proposal network for actor locations.
4.- Recognizing actions often requires looking beyond just the person, focusing on other people and objects in the scene.
5.- Self-attention-based solution using transformer architecture is proposed to encode context for actor representation.
6.- Initial actor representation is used to extract relevant regions from the full video representation.
7.- Video representation is projected into key and value embeddings, and actor representation is used for dot product attention.
8.- Weighted sum of values is added back to original actor features, creating an updated actor representation.
9.- Action transformer block takes initial actor representation, encodes video context, and outputs updated actor representation.
10.- Action transformer blocks are plugged in after initial actor representation, along with video features.
11.- Multiple layers of action transformer blocks can be organized arbitrarily, e.g., two cross three configuration.
12.- Final feature is trained for classification regression loss, similar to FasterR-CNN, using an action transformer head.
13.- Replacing i3D head with action transformer gave a 4% performance improvement; using both together yielded the best results.
14.- The model achieved state-of-the-art performance at the time of publication.
15.- Key and value embeddings in action transformer blocks can be visualized using PCA and color-coding.
16.- The model implicitly learns to track people in the video, both at a semantic and instance level.
17.- One action transformer head tracks people semantically by projecting them to the same embedding, while another tracks at an instance level.
18.- Attention maps show the model focusing on other people's faces, hands, and objects in the scene.
19.- The model performs well for most common action classes.
20.- Additional results demonstrate semantic and instance level embeddings, and attention focusing on relevant people and objects.
Knowledge Vault built byDavid Vivancos 2024